OWOD复现
项目环境:python3.7(python3.8)、cuda11.3、pytorch1.10
论文地址:https://arxiv.org/abs/2103.02603
代码地址:https://github.com/JosephKJ/OWOD
安装Detectron2
1、安装pytorch1.10 + torchvision0.11.0 + opencv
一开始没注意,安装了1.12的pytorch,结果官方给的文档上只到1.10,复现还是不要挑战高版本是否兼容了,尝试了一下pytorch版本降级,如下,但是没成功,还是1.12的。
conda install pytorch=0.1.10 -c soumith 果断退出虚拟环境,再建一个。
在这里 找对应1.10版本的pytorch,顺带torchvision也一起下了
conda create -n OWOD2 python=3.7
# CUDA 11.3
conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cudatoolkit=11.3 -c pytorch -c conda-forge报错了!!
(OWOD2) root@autodl-container-d8b611b252-d52809bf:~# conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=11.3 -c pytorch -c conda-forge
Collecting package metadata (current_repodata.json): done
Solving environment: failed with initial frozen solve. Retrying with flexible solve.
Collecting package metadata (repodata.json): / (OWOD2) root@autodl-container-d8b611b252-d52809bf:~#添加清华源!(不行)
#添加镜像源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
#显示检索路径
conda config --set show_channel_urls yes
#显示镜像通道
conda config --show channels还是离线下载吧(成功)
离线下载网址:https://download.pytorch.org/whl/cu113/torch_stable.html
下载**torch-1.10.0+cu113-cp37-cp37m-linux_x86_64.whl**和torchvision-0.11.0+cu113-cp37-cp37m-linux_x86_64.whl,
上传到服务器,然后
pip install torch-1.10.0+cu113-cp37-cp37m-linux_x86_64.whl
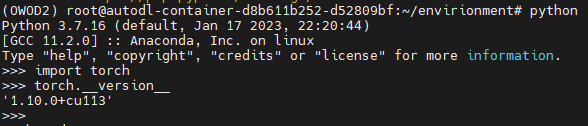
pip install torchvision-0.11.0+cu113-cp37-cp37m-linux_x86_64.whl查看一下torch版本怎么cuda版本也出来了,emmm,大抵是没毛病。
安装OpenCV
python -m pip install opencv-python -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com2、安装Detectron2
这里 获取对应版本的Detectron2
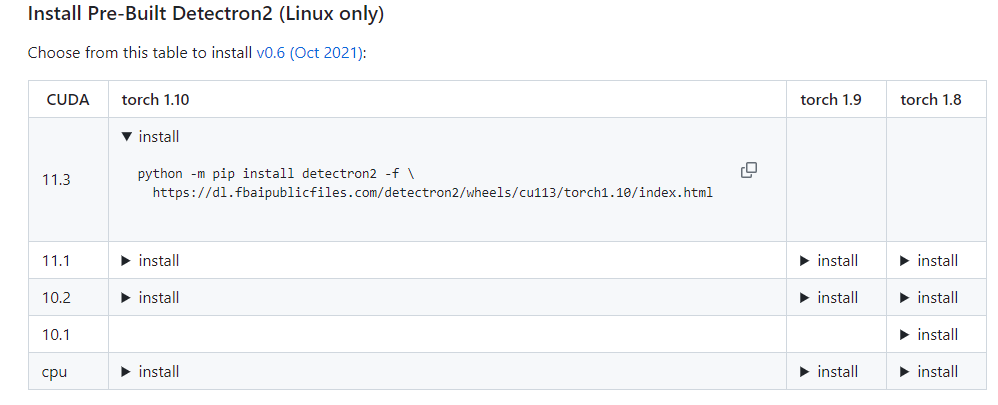
python -m pip install detectron2 -f \
https://dl.fbaipublicfiles.com/detectron2/wheels/cu113/torch1.10/index.html源代码构建
git clone https://github.com/facebookresearch/detectron2.git
python -m pip install -e detectron23、再下载gcc 和g++编译器
apt-get install gcc g++
4、安装依赖
pip install fvcore==0.1.1.post20200716
pip install 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'4.1报错:detectron2 0.6 requires fvcore<0.1.6,>=0.1.5, but you have fvcore 0.1.1.post20200716 which is incompatible.
那就换成pip install fvcore==0.1.5.post20210410吧
4.2报错:detectron2 0.6 requires pycocotools>=2.0.2, but you have pycocotools 2.0 which is incompatible.
解决:从这里 下载2.0.2的文件
cd到pycocotools所在目录。执行
python setup.py build_ext --inplace
python setup.py build_ext installconda list 查看pycocotools,安装成功
- 记得要用
pip uninstall pycocotools把之前2.0的卸载掉
在demo文件夹下放一张照片测试一下
python demo.py --config-file ../configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml --input 1.jpg --output ./result.jpg --opts MODEL.WEIGHTS detectron2://COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl报错: cannot import name 'cached_property' from 'functools'
搜索发现只有3.8以上才行????我尼玛搞了这么久你说得3.8,前面说大于等于3.6是吃屎了吗???
爷妥协了,重新建了3.8的环境,再来一遍,跑起来了


OWOD
1、数据集 文件夹
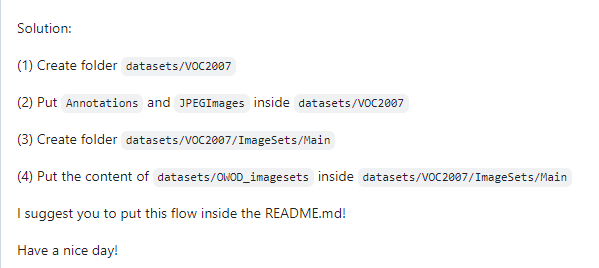
2、下载预训练模型
点击这里下载,放在OWOD-master下,找到OWOD-master/configs/OWOD/t1/t1_train.yaml,把预训练模型的文件路径替换原文件中weight的内容。
3、打包代码上传
linux下解压zip压缩文件unzip xxx.zip
| 选项 | 含义 |
|---|---|
| -d 目录名 | 将压缩文件解压到指定目录下。 |
| -n | 解压时并不覆盖已经存在的文件。 |
| -o | 解压时覆盖已经存在的文件,并且无需用户确认。 |
| -v | 查看压缩文件的详细信息,包括压缩文件中包含的文件大小、文件名以及压缩比等,但并不做解压操作。 |
| -t | 测试压缩文件有无损坏,但并不解压。 |
| -x 文件列表 | 解压文件,但不包含文件列表中指定的文件。 |
4、进入项目文件夹,配置detectron
python setup.py build develop- 不要使用该文件夹外部构建的Detectron2,运行代码时会报’Non-existent config key: OWOD’,具体原因是Detectron2的版本问题,所以一定要在OWOD内构建Detectron2
解决方法:在OWOD内部运行**python -m pip install -e ./**
5、开跑
python tools/train_net.py --num-gpus 1 --config-file ./configs/OWOD/t1/t1_train.yaml SOLVER.IMS_PER_BATCH 8 SOLVER.BASE_LR 0.0025 OUTPUT_DIR "./output/t1"- –num-gpus 1: 这个参数指定使用的GPU数量为1,表明训练将在单个GPU上进行。
- –config-file ./configs/OWOD/t1/t1_train.yaml: 这个参数指定了配置文件的路径,配置文件是训练过程中使用的设置和参数的集合。在这个例子中,配置文件的路径为 ./configs/OWOD/t1/t1_train.yaml。
- SOLVER.IMS_PER_BATCH 8: 这个参数设置了每个训练批次(batch)的图像数目为8。在训练过程中,将每次从数据集中选择8张图像用于训练。
- SOLVER.BASE_LR 0.0025: 这个参数设置了基础学习率(base learning rate)为0.0025。基础学习率是在训练过程中控制参数更新的速率的一个重要参数。
- OUTPUT_DIR “./output/t1”: 这个参数设置了输出目录的路径为 ./output/t1。在训练过程中,训练模型和其他输出文件将保存在这个目录中。
报错
- 报错:
**No module named 'reliability****'**
pip install reliability -i https://pypi.tuna.tsinghua.edu.cn/simple指定一下清华源
- 又报错:
module 'numpy' has no attribute 'str'.
查了一下是numpy版本的问题,我的是1.24.3,降级成1.22.0.但是另一个包要求numpy>=1.24.2,🤮
都tmd降级,numpy降到1.23
- 报错:
distutils‘ has no attribute ‘version‘
是setuptools版本问题
pip uninstall setuptools
pip install setuptools==59.5.0嗚嗚,out of memory了,batch_szie 只能設置爲2,開跑!!! 2000張圖片跑兩小時
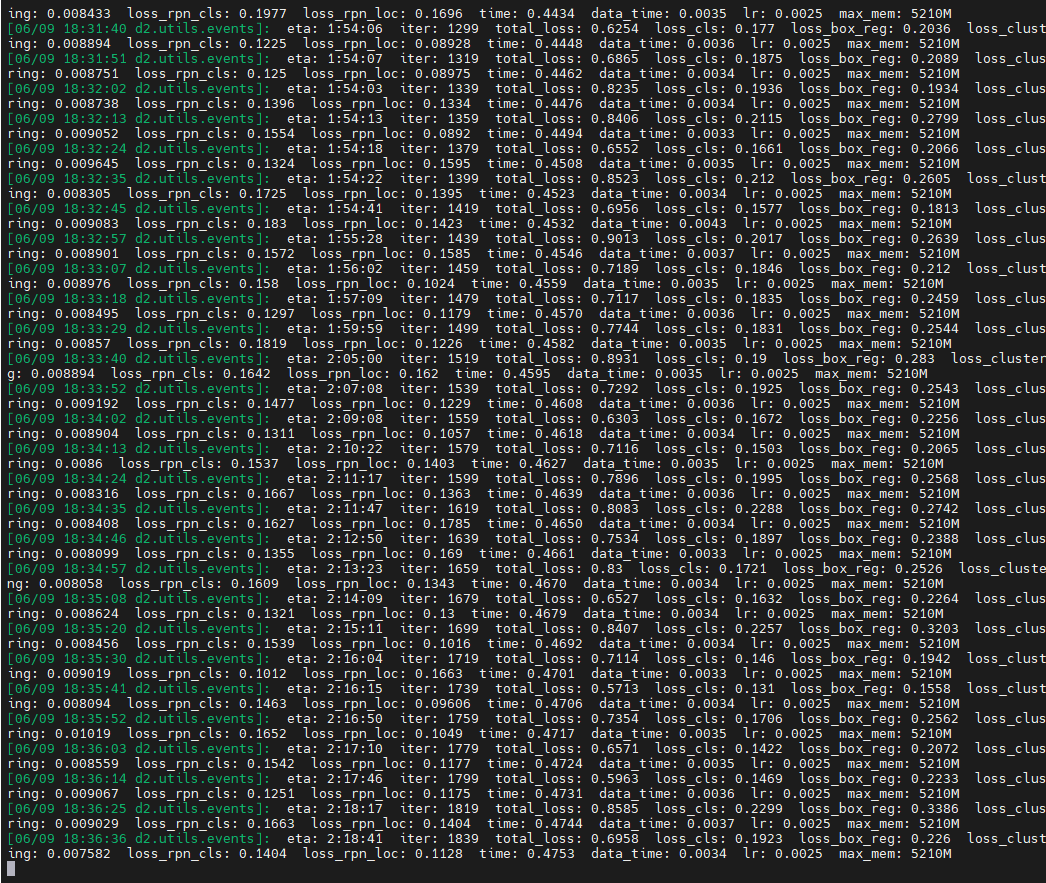
参数解释:
- eta: 2:00:55 这个指标表示预计训练完成所需的剩余时间。在这个例子中,预计还需要2小时、55分钟来完成训练。
- iter: 19 这个指标表示当前的迭代次数。在这个例子中,当前迭代次数为19次。
- total_loss: 2.895 这个指标表示总体损失(total loss)。总体损失是在训练过程中使用的一个综合指标,用于衡量模型的训练效果。在这个例子中,总体损失为2.895。
- loss_cls: 1.497 这个指标表示分类损失(classification loss)。分类损失是用于衡量模型分类任务的损失函数值。在这个例子中,分类损失为1.497。
- loss_box_reg: 0.2146 这个指标表示边界框回归损失(bounding box regression loss)。边界框回归损失是用于衡量模型边界框回归任务的损失函数值。在这个例子中,边界框回归损失为0.2146。
- loss_clustering: 0 这个指标表示聚类损失(clustering loss)。聚类损失是用于衡量模型聚类任务的损失函数值。在这个例子中,聚类损失为0。
- loss_rpn_cls: 0.6775 这个指标表示区域生成网络分类损失(region proposal network classification loss)。区域生成网络分类损失是用于衡量模型区域生成网络分类任务的损失函数值。在这个例子中,区域生成网络分类损失为0.6775。
- loss_rpn_loc: 0.199 这个指标表示区域生成网络定位损失(region proposal network localization loss)。区域生成网络定位损失是用于衡量模型区域生成网络定位任务的损失函数值。在这个例子中,区域生成网络定位损失为0.199。
- time: 0.4011 这个指标表示当前迭代的耗时。在这个例子中,当前迭代的耗时为0.4011秒。
- data_time: 0.0515 这个指标表示数据加载的耗时。在这个例子中,数据加载的耗时为0.0515秒。
- lr: 0.00047703 这个指标表示学习率(learning rate)的值。学习率是控制模型参数更新的速率的一个重要超参数
单张图片测试:
python demo.py --config-file /root/python_work/OWOD-master/configs/OWOD/t1/t1_test.yaml --input 2.jpg --output 2_res.jpg --opt MODEL.WEIGHTS /root/python_work/OWOD-master/output/t1/model_final.pth
两千张图片训出来的果然不行,柜子检测成car了。而且还有一个问题,就是这2000张图片没有按类别进行挑选,导致不知道某一个类有没有经过训练,也就无法测试是不是新类要标注为unknown。

可视化代码里要求output文件夹下有一个energy_dist.pkl文件,输出里面么得这个文件,稀碎。。。
cfg_file = "/root/python_work/OWOD-master/configs/OWOD/t1/t1_test.yaml"
model = '/root/python_work/OWOD-master/output/t1/model_final.pth'
im = cv2.imread("/root/python_work/OWOD-master/datasets/VOC2007/JPEGImages/" + file_name + ".jpg")
param_save_location = os.path.join('/root/python_work/OWOD-master/output/t1_clustering_val/energy_dist_' + str(20) + '.pkl')其他
1、查看服务器CUDA版本
nvcc -V
2、创建虚拟环境报错了!
CommandNotFoundError: Your shell has not been properly configured to use 'conda deactivate'.
To initialize your shell, run
$ conda init <SHELL_NAME>解决:
conda init bash4、查看torch版本
>>> import torch
>>> torch.__version__
'1.12.1'参考:
[OWOD复现过程总结_wangyanhuaa的博客-CSDN博客](https://blog.csdn.net/wangyanhuaa/article/details/129970265#:~:text=detectron2搭建成功后即可复现OWOD 1.下载OWOD代码。 2. 进入项目文件夹(cd OWOD-master),,激活环境,输入语句配置detectron python setup.py build develop)