MindSpeed-LLM训练Qwen.2.5-coder流程
1、昇腾镜像仓库
3、用户指南
4、参考流程
拉取镜像创建容器

在镜像仓库搜索mindspeed-llm找到合适版本的镜像点击立即下载
下载镜像
docker run -itd --privileged --name=LLM-2025-rc1 --net=host \
--shm-size 200g \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /usr/local/sbin:/usr/local/sbin \
-v /etc/hccn.conf:/etc/hccn.conf \
-v /home/zhij:/home/zhij \
swr.cn-south-1.myhuaweicloud.com/ascendhub/mindspeed-llm:2025.rc1-arm \
bash
#进入容器
docker exec -it LLM-2025-rc1 /bin/bashMindSpeed LLM及相关依赖安装
# 设置环境变量
source /usr/local/Ascend/ascend-toolkit/set_env.sh
source /usr/local/Ascend/nnal/atb/set_env.sh
# 安装MindSpeed加速库
git clone https://gitee.com/ascend/MindSpeed.git
cd MindSpeed
git checkout 2.0.0_core_r0.8.0
pip install -r requirements.txt
pip3 install -e .
cd ..
# 准备MindSpeed-LLM及Megatron-LM源码
git clone https://gitee.com/ascend/MindSpeed-LLM.git
git clone https://github.com/NVIDIA/Megatron-LM.git
cd Megatron-LM
git checkout core_r0.8.0
cp -r megatron ../MindSpeed-LLM/
cd ../MindSpeed-LLM
git checkout 2.0.0
pip install -r requirements.txt # 安装其余依赖库使用镜像创建的依赖应该没什么问题,这里服务器无法使用git,我是clone到本地上传到服务器,还挺方便的。建议不要下载zip版本,可能会因版本问题出现错误。在使用git checkout xxx切换分支时,会提示本地有未保存的修改,这是因为更近版本的代码也同时存在,直接丢弃即可。
git reset --hard HEAD下载模型权重
从huggingface下载Qwen/Qwen2.5-Coder-7B权重,同样是使用git下载到本地上传到服务器
在MindSpeed-LLM 下新建文件夹↓,将下载的文件放在qwen25-coder-7b-hf下
mkdir -p ./model_from_hf/qwen25-coder-7b-hf
cd ./model_from_hf/qwen25-coder-7b-hf验证模型完整性
import torch
import torch_npu
import numpy as np
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfig
def set_device(device_id):
torch.npu.set_device(torch.device(f"npu:{device_id}"))
def load_model(load_dir):
"""load model"""
config = AutoConfig.from_pretrained(load_dir, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(load_dir, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(load_dir, trust_remote_code=True).npu().eval()
return tokenizer, model
if __name__ == "__main__":
set_device(1)
load_dir = "./model_from_hf/qwen25-coder-7b-hf"
tokenizer, model = load_model(load_dir)
print(model)可以输出模型配置代表成功
转换权重
MindSpeed-LLM有两种模式下得大模型训练,分别是Mcore、Legacy。关于两种模式的差异,社区上并未给出任何功能定位解释,不过通过Readme特性解释可以看出,相较于legacy,Mcore模式下得大模型训练做了更多的并行加速特性支持,如长序列并行优化、MOE专家并行优化等高阶优化特性支持,即Mcore模式下的大模型训练性能会由于legacy,至于有了更高性能的mcore模式,为什么还要并行存在legacy,社区给的解释是:legacy为早期出版本模式,很多商用客户基于此模式在做版本维护,不能随意日落。
这里选择的是mcore模式,转换权重文件的路径为MindSpeed-LLM/examples/mcore/qwen25_coder/pretrain_qwen25_coder_7b_32k_ptd.sh ,根据自己配置修改参数。
- –target-tensor-parallel-size 2 张量并行度(TP),将模型的单个层(如注意力头、MLP层)的参数水平拆分到 4 个设备上
- –target-pipeline-parallel-size 2 流水线并行度(PP),将模型垂直拆分成 2 个连续阶段
- 总卡数 = 张量并行度(TP) × 流水线并行度(PP) × 数据并行度(DP),MindSpeed中没有显示设置DP的地方,通过 总卡数 / (TP × PP)自动计算。后面训练脚本中要同步修改 TP和PP。
# 修改 ascend-toolkit 路径
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# 设置需要的权重转换参数
python convert_ckpt.py \
--use-mcore-models \
--model-type GPT \
--load-model-type hf \
--save-model-type mg \
+ --target-tensor-parallel-size 2 \
+ --target-pipeline-parallel-size 2 \
--add-qkv-bias \
+ --load-dir ./model_from_hf/qwen25-coder-7b-hf/ \
+ --save-dir ./model_weights/qwen25-coder-7b-mcore/ \
+ --tokenizer-model ./model_from_hf/qwen25-coder-7b-hf/tokenizer.json \
--model-type-hf llama2 \
--params-dtype bf16
# --num-layer-list 11, 13, 19, 21 参数根据需要添加注:修改脚本尽量使用vim修改,打开记事本修改后python命令可能被当作Shell命令执行 或 window下的换行符\r无法识别
下载数据集
使用了一个自己的EvolInstruct-900.jsonl数据集,形式为:{"instruction": "xxx", "output": "xxxx"},放在dataset目录下。
mkdir dataset数据集预处理
【–input】
可以直接输入到数据集目录或具体文件,如果是目录,则处理全部文件, 支持 .parquet \ .csv \ .json \ .jsonl \ .txt \ .arrow 格式, 同一个文件夹下的数据格式需要保持一致
【–json-keys】
从文件中提取的列名列表,默认为 text,可以为 text, input, title 等多个输入 等多个输入,结合具体需求及数据集内容使用
python ./preprocess_data.py \
--input ./dataset/EvolInstruct-900.jsonl \
--tokenizer-name-or-path ./model_from_hf/qwen25-coder-7b-hf/ \
--tokenizer-type PretrainedFromHF \
--output-prefix ./dataset/EvolInstruct-900 \ #转换后输出文件的文件名前缀
--json-keys instruction output \ #根据数据集中的关键词进行分割
--workers 4 \
--log-interval 1000 成功后多了下面四个文件,按不同的json-keys分开,生成.bin和.idx文件
预训练时,数据集路径输入 ./dataset/EvolInstruct-900_instruction_document 即可
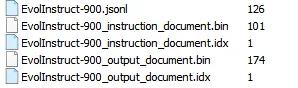
转换数据集
预训练
启动脚本为MindSpeed-LLM/examples/mcore/qwen25_coder/pretrain_qwen25_coder_7b_32k_ptd.sh,配置参数
export ASCEND_RT_VISIBLE_DEVICES=4,5,6,7
NPUS_PER_NODE=4
# please fill these path configurations
CKPT_LOAD_DIR="./model_weights/qwen25-coder-7b-mcore/"
CKPT_SAVE_DIR="./ckpt/qwen25-coder-7b"
DATA_PATH="/dataset/EvolInstruct-900_instruction_document"
TOKENIZER_MODEL="./model_from_hf/qwen25-coder-7b-hf/"
TP=2
PP=2
SEQ_LEN=1638- 1,2设置npu数量及id号
- CKPT_LOAD_DIR:转换后的权重路径
- CKPT_SAVE_DIR:训练后权重保存路径
- DATA_PATH:数据集路径
- TOKENIZER_MODEL:分词器路径
- TP、PP 与前面统一
- SEQ_LEN:默认是31K,基本都会OOM,修改到几千即可
在MindSpeed-LLM目录下启动
bash examples/mcore/qwen25_coder/pretrain_qwen25_coder_7b_32k_ptd.sh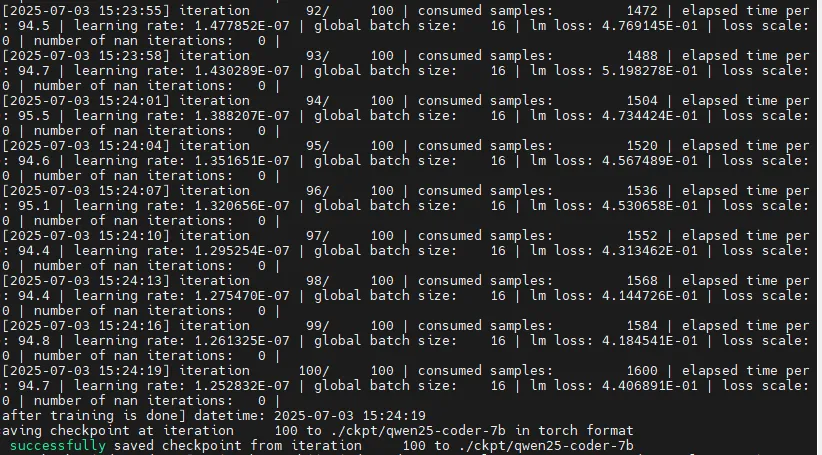
训练结果