高效添加导航站点
hexo + buttterfly中自带一个友联页,我用它来记录一些神奇的小网站。因为是静态的,无后台,想要添加一个网址链接,就要在links.yml文件中修改如下四项。先复制粘贴前面的格式,然后获取网址图标保存在source/img文件夹下,再写入该文件中。添加友联一次性并不会添加太多。而导航链接长久不更新积攒了好多,一个一个写太麻烦了。于是写一个程序,输入网址链接与对该网站的简介,自动在博客目录下生成添加后的link.yml文件,覆盖原先的
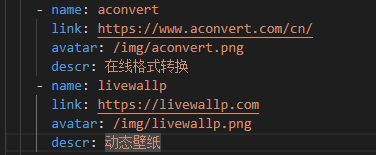
读取TXT
将要添加的站点信息写入txt文件,每一行分别为网址链接,简介, 要加入的分组,用空格隔开。例:
http://www.baidu.com 百度一下,你就知道 友情链接
http://www.google.com 谷歌啥都能搜 神秘学读入信息
list_website = []
list_descri = []
list_class = [] #放在那个分组下
def getTxT(txt_path):
with open(txt_path, "rb") as w:
lines = w.readlines()
for line in lines:
# parts = line.strip().split(' ')
line_str = line.decode('utf-8').strip()
parts = line_str.split(' ')
list_website.append(parts[0])
list_descri.append(parts[1])
list_class.append(parts[2])获取网址信息
获取网站图标
使用的是现成的api,在后面加上网址即可
https://api.xinac.net/icon/?url=
https://api.qqsuu.cn/api/get?url=
https://f.ydr.me/
https://api.byi.pw/favicon/?url=
https://favicon.link/
https://favicon.yandex.net/favicon/
http://favicon.cccyun.cc/
https://statics.dnspod.cn/proxy_favicon/_/favicon?domain=将获取到的网站图标保存到source/img文件夹下,用来给links.yml调用。保存图片函数:
urllib.request.urlretrieve(getImg,localfileName)getImg: 图标链接
localfileName:保存到本地的链接名称
获取网站标题
使用requests与BeautifulSoup
res = requests.get(url)
res.enconding = 'utf-8'
soup = BeautifulSoup(res.text,'lxml')
title = soup.title.text完整代码
add_new_link = """
name: {name}
link: {link}
avatar: {avatar}
descr: {descr}
"""
def getUrlMessange(link, descr, saveSource):
# 返回yaml格式的新增站点
function = "https://api.xinac.net/icon/?url="
getImg = function + link
res = requests.get(link)
res.enconding = 'utf-8'
soup = BeautifulSoup(res.text,'lxml')
title = soup.title.text
urllib.request.urlretrieve(getImg, saveSource + title + '.png')
avatar = '/img/' + title + '.png'
lianjie = add_new_link.format(name = title,link = link,avatar = avatar, descr = descr)
lianjie = yaml.safe_load(lianjie)
return lianjieyaml.safe_load()将字符串转换为yaml格式字典
写入Yaml文件
def writeYaml(lianjie_yaml, add_class_name, ayml):
# yaml格式的新增站点, 放入组的名称, 要写入的文件
for n in range(len(ayml)):
class_name = ayml[n]['class_name']
if(class_name == add_class_name):
ayml[n]["link_list"].append(lianjie_yaml)这个地方要注意写入信息的有重复的话,会自动生成键&-id001,要注意去重,去重代码。加一个判断是否已经存在:
def is_link_exits(link, ayml):
for entry in ayml:
for link_list in entry.get('link_list', []):
if link_list.get('link') == link:
return True
return False主函数:
def main():
getTxT(website)
# r+表示读写
with open(targetFile, 'r+', encoding='utf-8') as f:
ayml = yaml.load(f, Loader=yaml.Loader)
for k in range(len(list_website)):
link = list_website[k]
descr = list_descri[k]
class_name = list_class[k]
if is_link_exits(link, ayml):
print(link + "已存在")
continue
lianjie = getUrlMessange(link, descr, saveSource)
writeYaml(lianjie, class_name, ayml)
# 文件清空,将光表移动至开始
f.seek(0)
f.truncate()
yaml.dump(ayml, f, allow_unicode=True, sort_keys=False)规范文件名
由于图片是按照网站title命名的,难免会出现不符合文件名规范的标题,需要处理
def normalize_filename(filename):
# 去除非法字符
filename = re.sub(r'[\\/*?:"<>|]', '', filename)
# 将空格替换为下划线
filename = re.sub(r'\s+', '_', filename)
# 将所有字母转换为小写
filename = filename.lower()
return filename附:
1、写入yaml文件是,键值对默认是按照’键’ 的首字母顺序排序,使用 yaml.dump(ayml, f, sort_keys=False按原先顺序写入
2、编码问题,都加上准没错
# coding:utf-8- getTXT()中
line_str = line.decode('utf-8').strip() - 写入yaml时
yaml.dump(ayml, f, allow_unicode=True, sort_keys=False) - request解析网页
res.encoding = "utf-8"
最后
- 使用时将py文件和存放信息的
website.txt文件放在博客根目录下,运行即可。图标文件保存在\source\img下 - 写入分组目前只能加入已有分组,创建新的分组(TODO)
- 每个网站图标的爬取方式不一定一样,用别人的API更保险

成功截图
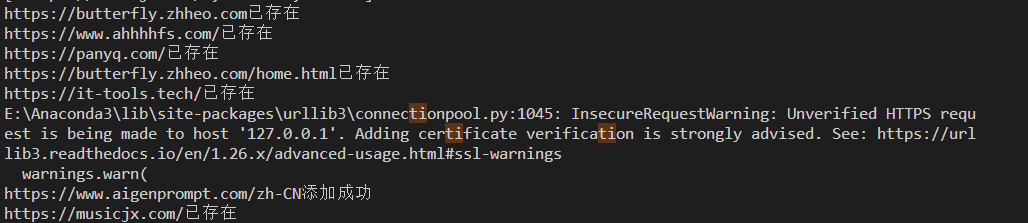
全部代码:
#!/usr/bin/python
# coding:utf-8
import requests
import urllib
from bs4 import BeautifulSoup
import yaml
import os
create_new_class = """
- class_name: {class_name}
class_desc:
link_list:
name: {name}
link: {link}
avatar: {avatar}
descr: {descr}
"""
add_new_link = """
name: {name}
link: {link}
avatar: {avatar}
descr: {descr}
"""
current_directory = os.path.dirname(os.path.abspath(__file__))
website = current_directory + '\website.txt'
targetFile =current_directory +'\source\_data\link.yml'
saveSource = current_directory + '\source\img\\'
list_website = []
list_descri = []
list_class = [] #放在那个分组下
import re
def normalize_filename(filename):
# 去除非法字符
filename = re.sub(r'[\\/*?:"<>|]', '', filename)
# 将空格替换为下划线
filename = re.sub(r'\s+', '_', filename)
# 将所有字母转换为小写
filename = filename.lower()
return filename
def getUrl(url, descr, saveSource):
function = "https://api.xinac.net/icon/?url="
getImg = function + url
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
res = requests.get(url, headers=headers, verify=False)
res.encoding = "utf-8"
# res.enconding = res.apparent_encoding
# print(res.text)
soup = BeautifulSoup(res.text,'lxml')
title = soup.title.text.replace(" ","")
title = normalize_filename(title)
# print(title)
urllib.request.urlretrieve(getImg, saveSource + title + '.png')
avatar = '/img/' + title + '.png'
lianjie = add_new_link.format(name = title,link = url,avatar = avatar, descr = descr)
lianjie = yaml.safe_load(lianjie)
return lianjie
def getTxT(txt_path):
with open(txt_path, "rb") as w:
lines = w.readlines()
for line in lines:
# parts = line.strip().split(' ')
line_str = line.decode('utf-8').strip()
parts = line_str.split(' ')
print(parts)
if len(parts) >= 3:
list_website.append(parts[0])
list_descri.append(parts[1])
list_class.append(parts[2])
def is_link_exits(link, ayml):
for entry in ayml:
for link_list in entry.get('link_list', []):
if link_list.get('link') == link:
return True
return False
def writeYaml(lianjie_yaml, add_class_name, ayml):
# yaml格式的新增站点, 放入组的名称, 要写入的文件
for n in range(len(ayml)):
class_name = ayml[n]['class_name']
if(class_name == add_class_name):
ayml[n]["link_list"].append(lianjie_yaml)
# def getClassNames():
# class_names = []
# with open(targetFile, 'r+', encoding='utf-8') as f:
# ayml = yaml.load(f, Loader=yaml.Loader)
# for n in range(len(ayml)):
# class_name = ayml[n]['class_name']
# class_names.append(class_name)
# return class_names
def main():
getTxT(website)
if not os.path.exists(saveSource):
os.makedirs(saveSource)
# classNames = getClassNames()
with open(targetFile, 'r+', encoding='utf-8') as f:
ayml = yaml.load(f, Loader=yaml.Loader)
print(ayml)
for k in range(len(list_website)):
link = list_website[k]
descr = list_descri[k]
class_name = list_class[k]
if is_link_exits(link, ayml):
print(link + "已存在")
continue
# lianjie = getUrlMessange(link, descr, saveSource)
lianjie = getUrl(link, descr, saveSource)
writeYaml(lianjie, class_name, ayml)
print(link + "添加成功")
f.seek(0)
f.truncate()
yaml.dump(ayml, f, allow_unicode=True, sort_keys=False, default_style='')
main()本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 桥边红药的博客!


评论